网络安全实验要写一个端口扫描程序,写完后发现太慢了,然后就只有学习学习多线程是如何实现的。
线程的概念
-
Why线程Not进程?
因为创建进程带来的开销较大,进程之间进行数据交换需要特殊的IPC技术。而且最要命的是“上下文切换”:如果运行进程A后需要紧接着运行进程B,就应该将进程A相关信息移出内存,并读入进程B相关信息。这就是上下文切换。但此时进程A的数据将被移动到硬盘,所以上下文切换需要很长时间。即使通过优化加快速度,也会存在一定的局限。
线程可以理解成一种轻量级进程,相比进程,线程的创建更快、上下文切换更快、线程间交换数据无需特殊的技术。
-
线程和进程的差异
每个进程的内存空间都保存全局变量的数据区、堆、栈,每个进程都有这种独立空间。结构表示如下:
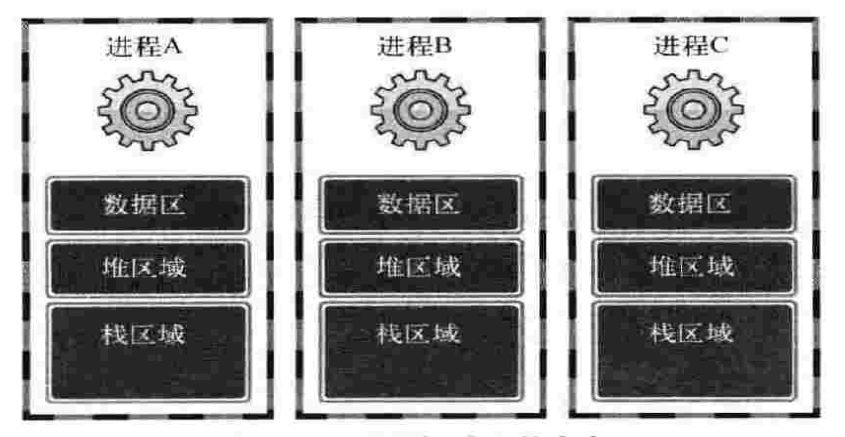
如果只是单纯的为了加快代码的执行速度,显然这种方式不够高效。
线程上下文切换不需要切换数据区和堆,并且可以利用数据区和堆进行数据交换。线程的内存结构如下:
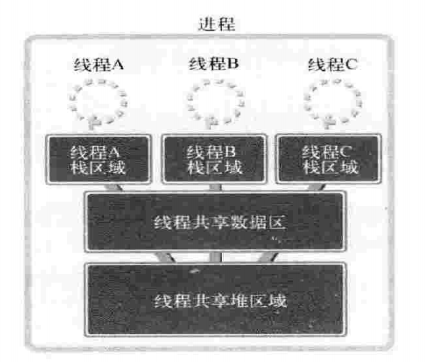
实际上操作系统、进程、线程的关系如下:
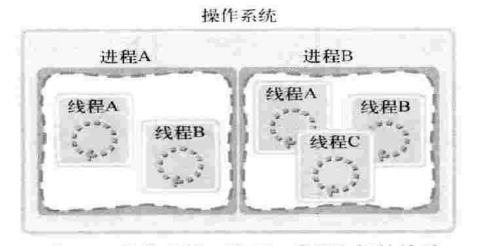
进程:在操作系统构成单独执行流的单位
线程:在进程构成单独执行流的单位
线程的创建及运行
-
头文件:#include<pthread.h>
-
编译选项:要加
-lpthread后缀 -
创建线程:
pthread_t t_id;//线程号 pthread_create(&t_id,NULL,thread_main,(void*)&thread_param) //thread_main 是要进行多线程的函数 //(void*)&thread_param 是要传的参数给thread_main,如果要传多个参数,构造结构体下面举一个栗子,看具体怎么实现:
#include<stdio.h> #include<pthread.h> #include<unistd.h> void* thread_main(void *arg); int main(int argc,char *argv[]) { pthread_t t_id; int thread_param=5; if(pthread_create(&t_id,NULL,thread_main,(void*)&thread_param)!=0) { puts("pthread_create() error"); return -1; } sleep(2); puts("end of main"); return 0; } void* thread_main(void *arg) { int i; int cnt=*((int*)arg); for(i=0;i<cnt;i++) { sleep(1); puts("running thread"); } return NULL; }这样就实现了一个函数通过多线程调用了多次。实现的过程如下:
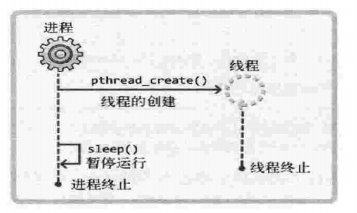
但是实际上还存在问题,因为真正的项目运行过程中,我们是无法估计sleep()的时长的。如果sleep()太短,导致线程还没终止,进程就提前终止了,这样整个内存都会销毁掉。那么只能z设置一个标记,使得线程运行结束后主函数的进程才会终止。
我们可以通过
pthread_join()函数实现该功能,再举个栗子#include<stdio.h> #include<stdlib.h> #include<string.h> #include<pthread.h> #include<unistd.h> void* thread_main(void *arg); int main(int argc,char *argv) { pthread_t t_id; int thread_param=5; void * thr_ret; if(pthread_create(&t_id,NULL,thread_main,(void*)&thread_param)!=0) { puts("pthread_create() error"); return -1; } if(pthread_join(t_id,&thr_ret)!=0)//thr_ret保存返回给主函数的值的地址 { puts("pthread_join() error"); return -1; } printf("Thread return message:%s \n",(char*)thr_ret); free(thr_ret); return 0; } void* thread_main(void *arg) { int i; int cnt=*((int*)arg); char * msg=(char *)malloc(sizeof(char)*50); strcpy(msg,"Hell,I'am thread~\n"); for ( i = 0; i < cnt; i++) { sleep(1);puts("running thread"); } return (void*)msg; }那么这样的流程可以用下面的图来表示:
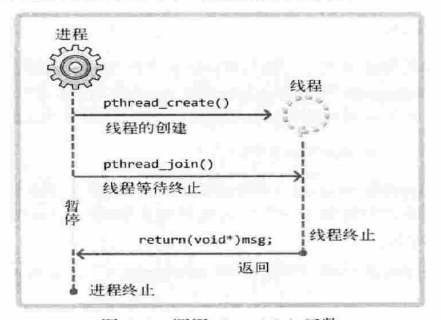
但是实际上这样还有一个隐含的bug,稍后将会提到。
至此,整个工作线程模型如下:
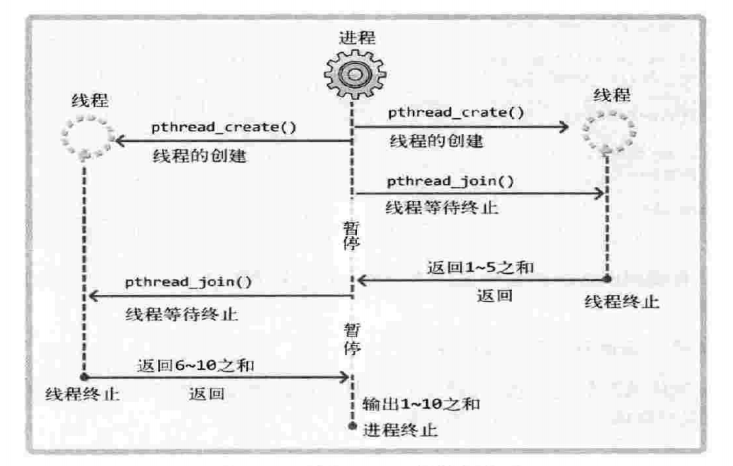
线程的临界区问题和线程同步
-
Why?
首先通过如下的一个事例来进行说明
#include<stdio.h> #include<pthread.h> void * thread_summation(void * arg); int sum=0; int main(int argc,char* argv[]) { pthread_t id_t1,id_t2; int range1[]={1,5}; int range2[]={6,10}; pthread_create(&id_t1,NULL,thread_summation,(void*)range1); pthread_create(&id_t2,NULL,thread_summation,(void*)range2); pthread_join(id_t1,NULL); pthread_join(id_t2,NULL); printf("result:%d\n",sum); return 0; } void * thread_summation(void * arg) { int start=((int*)arg)[0]; int end=((int*)arg)[1]; while (start<=end) { sum+=start; start++; } return NULL; }理论上,运行的结果一直是55,但是实际上并不是,多次的运行结果小于55,这是为什么呢?
假设两个线程中的数值分别为A、B,全局变量的值为C。
假设C的初始值为55,若两个线程同时取数,则线程1中A=C;C=A+1=55+1=56,线程2中也是B=C;C=C+1=56,实际上我们想要的效果是线程1先运行A=C=55;C=A+1=56,然后线程2中B=C=56;C=B+1=57;显然这个问题是两个线程同时对一个公共区域的数据进行写操作造成的问题。
临界区不是全局变量,而是多线程中的函数造成的问题,那么我们得解决这个问题,也就是我们要做线程同步。
-
How?
-
互斥量
使用函数:
#include< pthread.h> int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* attr); int pthread_mutex_destroy (pthread_mutex_t mutex); int pthread_ mutex_lock(pthread_mutex_t * mutex); //临界区的开始 //。。。 //临界区的结束 int pthread_mutex_unlock(pthread mutex t mutex)具体使用栗子:
#include .... #define NUM_THREAD 100 void * thread_inc(void * arg); void * thread_des(void * arg); pthread_mutex_t mutex; int main() { pthread_t thread_id[NUM_THREAD]; int i; pthread_mutex_init(&mutex,NULL); for(i=00;i<NUM_THREAD;i++) { if(...) pthread_create(&thread_id[i],NULL,thread_inc,NULL); else pthread_create(&thread_id[i],NULL,thread_des,NULL); } for(i=0;i<NUM_THREAD;i++) { pthread_join(thread_id[i],NULL); } pthread_mutex_destroy(&mutex); return 0; } void * thread_inc(void * arg) { //... pthread_mutex_lock(&mutex); //... //A //... pthread_mutex_unlock(&mutex); return NULL; } void * thread_dec(void * arg) { //... pthread_mutex_lock(&mutex); //... //B //... pthread_mutex_unlock(&mutex); return NULL; }需要注意的是,线程退出临界区的时候,如果忘了调用pthread_mutex_unlock()函数,那么其他进入临界区的线程就一直是阻塞状态,这样就会出现“死锁”。
实际上,lock和unlock函数的调用花费的时间起始也挺多,虽然解决的之前的问题,但是性能较差,尤其是临界区较大的情况。
-
信号量
信号量与互斥量极其相似。
#include <semaphore.h> int sem_init(sem_t * sem, int shared, unsigned int value); //sem:创建信号量时传递保存信号量的变量地址值 //pshared:传递其他值时,创建可由多个进程共享的信号量;0使为仅允许一个进程内部使用 //value:指定创建的信号量的初始值 int sem_destroy (sem_t * sem) int sem_wait(sem_t * sem);//信号量变为0 //临界区的开始 //。。。 //临界区的结束 int sem_post(sem_t * sem);///信号量变为1调用 scm_init函数时,操作系统将创建信号量对象,此对象中记录着“信号量值”(SemaphoreValue)整数。该值在调用 sempost函数时增1,调用 sem wait函数时减1。但信号量的值不能小于0,因此,在信号量为0的情况下调用 sem_wait函数时,调用函数的线程将进入阻塞状态(因为函数未返回)。当然,此时如果有其他线程调用 sem_post函数,信号量的值将变为1,而原本阻塞的线程可以将该信号量重新减为0并跳出阻塞状态。实际上就是通过这种特性完成临界区的同步操作,可以通过如下形式同步临界区(假设信号量的初始值为1)
举个例子,按照线程A、线程B的顺序访问变量num,且线程同步:
#include<stdio.h> #include <pthread.h> #include <semaphore.h> void * read(void * arg); void* accu(void * arg); static sem_t sem_one; static sem_t sem_two; static int num; int main(int argc, char *argv[]) { pthread_t id_t1, id_t2; sem_init(&sem_one, 0, 0); sem_init(&sem_two, 0, 1); pthread_create(&id_t1, NULL, read, NULL); pthread_create(&id t2, NULL, accu, NULL); pthread_join(id_t1, NULL); pthread_join(id_t2, NULL); sem_destroy(&sem_one); sem_destroy(&sem_two); return 0: } void * read(void * arg) { int i; for(1=0;1<5;i++) { fputs("Input num:", stdout); sem_wait(&sem_two); scanf("%d",&num); sem_post(&sem_one); } return NULL; } void * accu(void * arg) { int sum=0,i; for(i=0;i<5;i++) { sem_wait(&sem_one); sum+=num; sem_post(&sem_two); } printf("Result:%d \n",sum); return NULL; }
-
线程的销毁
Linux线程并不是在首次调用的线程main函数返回时自动销毁,所以用如下2种方法之一加以明确。否则由线程创建的内存空间将一直存在。
- 调用pthread_join函数
- 调用pthread_detach函数
之前调用过 pthread_join函数。调用该函数时,不仅会等待线程终止,还会引导线程销毁。
但该函数的问题是,线程终止前,调用该函数的线程将进人阻塞状态。因此,通常通过pthread_detach函数调用引导线程销毁。
要注意的是pthread_join和pthread_detach函数不能同时使用