鉴于写第一个job踩的坑,今天多总结一下
MR的架构原理
MR基本架构思想
对付大数据并行处理--分而治之:
-
一个大数据若可以分为具有同样计算过程的数据块,并且这 些数据块之间不存在数据依赖关系,则提高处理速度的最好 办法就是采用“分而治之”的策略进行并行化计算
-
MapReduce采用了这种“分而治之”的设计思想,对相互 间不具有或者有较少数据依赖关系的大数据,用一定的数据 划分方法对数据分片,然后将每个数据分片交由一个节点去 处理,最后汇总处理结果
上升到抽象模型--Map与Reduce:
- MapReduce借鉴了函数式程序设计语言Lisp的设计思想
MR基本设计思想
-
用Map和Reduce两个函数提供了高层的并行编程抽象模型和接口, 程序员只要实现这两个基本接口即可快速完成并行化程序的设计
-
MapReduce的设计目标是可以对一组顺序组织的数据元素/记录进 行处理
-
现实生活中,大数据往往是由一组重复的数据元素/记录组成,例如, 一个Web访问日志文件数据会由大量的重复性的访问日志构成,对这种顺序式数据元素/记录的处理通常也是顺序式扫描处理
MR的主要功能
Mapreduce涉及的4个独立体:
-
客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的 工作
-
JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行
-
TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce 任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在 执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个
-
Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
MapReduce提供了以下的主要功能:
-
数据划分和计算任务调度:系统自动将一个作业(Job)待处理的大 数据划分为很多个数据块,每个数据块对应于一个计算任务(Task),并自动调度计算节点来处理相应的数据块。作业和任务调度功能主要 负责分配和调度计算节点(Map节点或Reduce节点),同时负责监控这些节点的执行状态,并负责Map节点执行的同步控制
-
数据/代码互定位:为了减少数据通信,一个基本原则是本地化数据 处理,即一个计算节点尽可能处理其本地磁盘上所分布存储的数据,这实现了代码向数据的迁移;当无法进行这种本地化数据处理时,再 寻找其他可用节点并将数据从网络上传送给该节点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻 找可用节点以减少通信延迟
-
系统优化:为了减少数据通信开销,中间结果数据进入Reduce节点前会 进行一定的合并处理;一个Reduce节点所处理的数据可能会来自多个 Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的 中间结果需使用一定的策略进行适当的划分处理,保证相关性数据发送 到同一个Reduce节点;此外,系统还进行一些计算性能优化处理,如对 最慢的计算任务采用多备份执行、选最快完成者作为结果
-
出错检测和恢复:以低端商用服务器构成的大规模MapReduce计算集群 中,节点硬件(主机、磁盘、内存等)出错和软件出错是常态,因此MapReduce需要能检测并隔离出错节点,并调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据存储的可靠性,用多备份冗余存储机制提高数据存储的可靠性,并能及时检测和恢复出错的数据
MR的运行详解
流程角度运作机制详解:
-
1.客户端编写好mapreduce程序,配置好mapreduce的作 业(也就是job)
-
2.提交job到JobTracker上
-
3.JobTracker分配一个新的job任务的ID值;检查输出目录 是否存在,如果存在就抛出错误给客户端;检查输入目录是 否存在,如果不存在同样抛出错误;根据输入计算输入分片 (Input Split),如果分片计算不出来也会抛出错误
-
4.以上检查都通过,JobTracker就会配置Job需要的资源
-
5.JobTracker初始化作业,将Job放入一个内部的队列,让 配置好的作业调度器能调度到这个作业
-
6.作业调度器初始化job,创建一个正在运行的job对象 (封装任务和记录信息),以便JobTracker跟踪job的状态 和进程
-
7.作业调度器获取输入分片信息(input split),每个分片 创建一个map任务
-
8.tasktracker运行一个简单的循环机制定期发送心跳给 jobtracker(间隔五秒,可配置),心跳是jobtracker和 tasktracker沟通的桥梁,通过心跳,jobtracker可以监控 tasktracker是否存活,也可以获取tasktracker处理的状态和问题, 同时tasktracker也可以通过心跳里的返回值获取jobtracker给它 的操作指令
-
9.分片执行任务,在任务执行时候jobtracker可以通过心跳机制 监控tasktracker的状态和进度,同时也能计算出整个job的状态和 进度,而tasktracker也可以本地监控自己的状态和进度
-
10.当jobtracker获得了最后一个完成指定任务的tasktracker操作 成功的通知时候,jobtracker会把整个job状态置为成功
-
11.然后当客户端查询job运行状态时候(异步操作),客 户端会查到job完成的通知的,任务执行完成
-
12.如果job中途失败,mapreduce也会有相应机制处理, 一般而言如果不是程序本身有bug,mapreduce错误处理 机制都能保证提交的job能正常完成,如果是程序本身bug, 任务在重复执行2~3次后,会结束执行,jobtracker会把整 个job状态置为失败
MR运行阶段:
-
1.输入分片(input split):在进行map计算之前,mapreduce 会根据输入文件计算输入分片(input split),每个输入分片 (input split)针对一个map任务,输入分片(input split)存 储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很 密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有 三个文件,大小分别是3mb、65mb和127mb,那么mapreduce 会把3mb文件分为一个输入分片(input split),65mb则是两个 输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如 合并小文件,那么就会有5个map任务将执行,而且每个map执 行的数据大小不均,这个也是mapreduce优化计算的一个关键点
-
2.map阶段:就是我们写的map函数,map函数效率相对 好控制,而且一般map操作都是本地化操作也就是在数据存 储节点上进行;map函数每次处理一行数据,map主要用 于数据的分组,为下一步reduce的运算做数据准备,map 的输出就是reduce的输入
-
3.combiner阶段:combiner阶段是可选的,combiner是一个 本地化的reduce操作,它是map运算的后续操作,主要是在map 计算出中间文件前做一个简单的合并重复key值的操作,使传入 reduce的文件变小,这样就提高了宽带的传输效率,毕竟 hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源, 但是combiner操作是有风险的,使用它的原则是combiner的输 入不会影响到reduce计算的最终输入,例如:如果计算只是求总 数,最大值,最小值可以使用combiner,但是做平均值计算使用 combiner的话,最终的reduce计算结果就会出错
-
4.shuffle阶段:将map的输出作为reduce的输入的过程就是shuffle了,这 个是mapreduce优化的重点地方。Shuffle一开始就是map阶段做输出操作, 一般mapreduce计算的都是海量数据,map输出时候不可能把所有文件都放 到内存操作,因此map写入磁盘的过程十分的复杂,更何况map输出时候要 对结果进行排序,内存开销是很大的,map在做输出时候会在内存里开启一 个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且 在配置文件里为这个缓冲区设定了一个阀值,默认是0.80(这个大小和阀值 都是可以在配置文件里进行配置),同时map还会为输出操作启动一个守护 线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容 写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的 数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么 map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存 操作,写入磁盘前会有个排序操作,就是在写入磁盘操作时候进行,不是在 写入内存时候进行的,如果我们定义了combiner函数,那么排序前还会执行 combiner操作.每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map 输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并 这些输出文件。这个过程里还会有一个Partitioner操作,Partitioner操作和map 阶段的输入分片(Input split)很像,一个Partitioner对应一个reduce作业,如 果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果 我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就 是reduce的输入分片,这个我们可以编程控制,主要是根据实际key和value的值, 根据实际业务类型或者为了更好的reduce负载均衡要求进行,这是提高reduce效 率的一个关键所在。到了reduce阶段就是合并map输出文件了,Partitioner会找 到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制 线程,这些线程默认个数是5个,我们也可以在配置文件更改复制线程的个数,这 个复制过程和map写入磁盘过程类似,也有阀值和内存大小,阀值一样可以在配 置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时 候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算 了
-
5.reduce阶段:我们编写的reduce函数,reduce的输入是 map的输出,reduce是主要的逻辑运算阶段,我们绝大部 分业务逻辑都是在reduce阶段完成的,并把最终结果存储 在hdfs上的
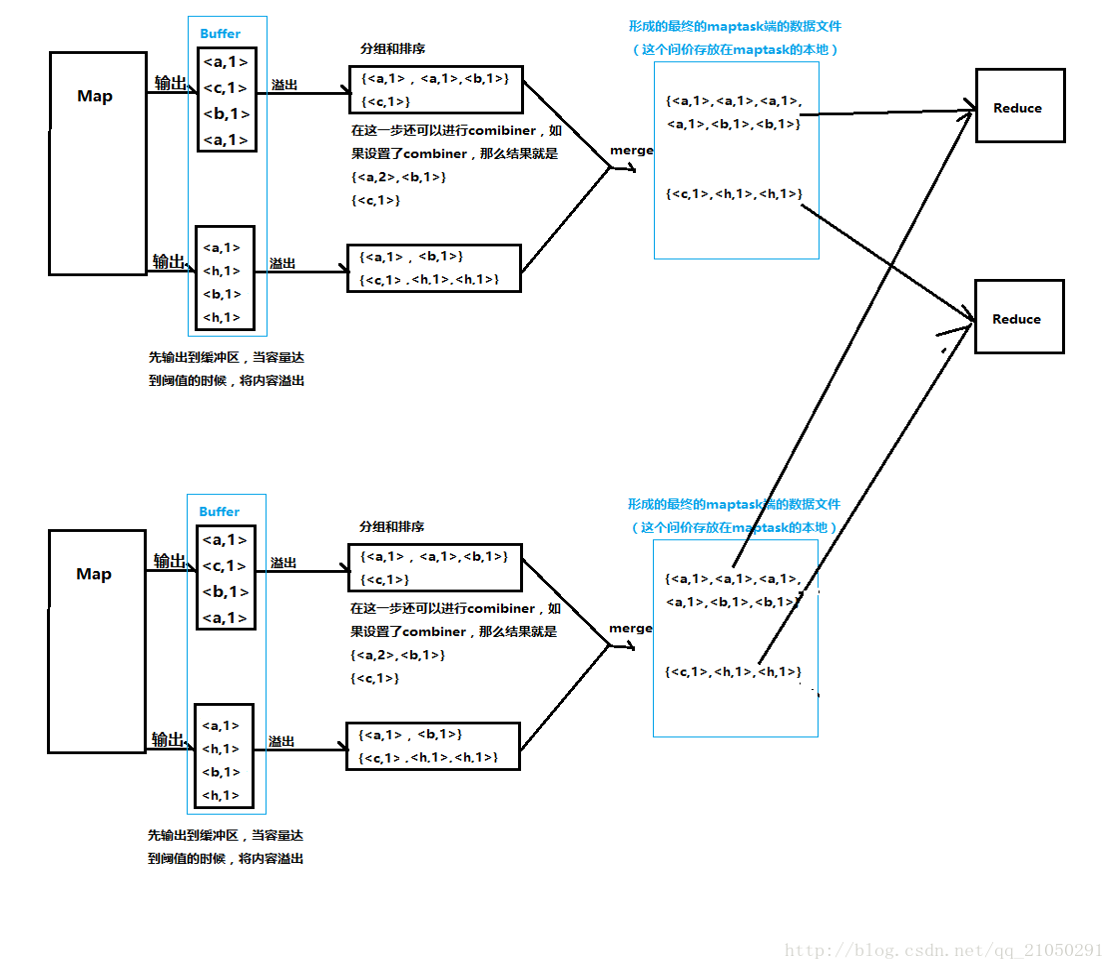
MR运作总结:
MR有四个独立实体:client、JobTracker、TaskTracker、 Hdfs
从两个角度可以解读MR的运作机制
常用的MR内置对象有八种,分别对应java中的一些常见数据类型,可以根据需要灵活选用:
| 名称 | 数据类型 |
|---|---|
| BooleanWritable | 标准布尔型数值 |
| ByteWritable | :单字节数值 |
| DoubleWritable | :双字节数值 |
| FloatWritable | 浮点数 |
| IntWritable | 整型数 |
| LongWritable | 长整型数 |
| Text | 使用UTF8格式存储的文本 |
| NullWritable | 当<key, value>中的key或value为空时使用 |
MR的代码实现
加入依赖jar包
Mapreduce函数的编写:
-
map函数
- 继承Mapper<Object, Object, Object, Object>
- 重写public void map(Object key, Object value, Context context) throws IOException, InterruptedException 方法
- map函数主要用于数据的清洗和原始处理
-
map函数的输入输出
- map函数每执行一次,处理一条数据
- map的输入,key默认是行号的偏移量,value是一行的内容
- context.write(Object, Object)方法输出
- map的输出是reduce的输入
-
reduce函数
- 继承Reducer<Object, Object, Object, Object>
- 重写public void reduce(Object key, Iterable
- reduce函数是主要的业务处理和数据挖掘部分
-
reduce函数的输入输出
- context.write(data, new IntWritable(1))方法输出
- reduce的输入时map的输出,但不是直接输出,而是按照相同 key汇总过后的集合
- context.write(Object, Object)方法输出
-
编写job
-
代码实现数数:
package com.bear; import java.io.IOException; import java.util.Arrays; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SortNum { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.245.129:9000"); Job job = Job.getInstance(conf, "numcount"); job.setJarByClass(SortNum.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class); FileInputFormat.addInputPath(job, new Path("/test/input/sortNumber.txt")); Path outputPath = new Path("/test/output/word"); FileSystem.get(conf).delete(outputPath, true); FileOutputFormat.setOutputPath(job, outputPath); boolean isSeccessful = job.waitForCompletion(true); HDFSUtil hdfsUtil = new HDFSUtil(conf); hdfsUtil.showResultIn(outputPath.toString()); System.exit(isSeccessful ? 0 : 1); } public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] nums = value.toString().split("\\s+"); IntWritable one = new IntWritable(1); Text text = new Text(); for (String num : nums) { text.set(num); context.write(text, one); } } } public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text value, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException { int sum = 0; IntWritable i = new IntWritable(); for (IntWritable intWritable : iterable) { sum += intWritable.get(); } i.set(sum); context.write(value, i); } } }
更详细的讲解可以参考Edison Zhou的这篇Hadoop学习笔记—4.初识MapReduce