SQL内容归纳
日期:2019年7月15日
SQL概述
数据库的概念
数据库:保存数据的容器
数据库的好处:
- 实现数据持久化
- 使用完整的管理系统统一管理,易于查询
DB:
数据库(database):存储数据的“仓库”。它保存了一系列有组织的数据
DBMS:
数据库管理系统(Database Management System)。数据库是通过DBMS创建和操作的容器
SQL:
结构化查询语言(Structure Query Language):专门用来与数据库通信的语言
SQL语言概述
SQL的优点:
- 不是某个特定数据库供应商专有的语言,几乎所有DBMS都支持SQL
- 简单易学
- 是一种强有力的语言,灵活使用其语言元素,可以进行非常复杂和高级的数据库操作
SQL语言分类
- DML(Data Mainipulation language):数据操纵语句,用于添加、删除、修改、查询数据库记录,并检查数据完整性
- DDL(Data Definition language):数据定义语句,用于库和表的创建、修改、删除
- DCL(Data Control language):数据控制语句,用于定义用户的访问 权限和安全级别。
DML
DML用于查询与修改数据记录,包括如下SQL语句:
- INSERT:添加数据到数据库中
- UPDATE:修改数据库中的数据
- DELETE:删除数据库中的数据
- SELECT:选择(查询)数据
SELECT是SQL语言的基础,最为重要
DDL
DDL用于定义数据库的结构,比如创建、修改或删除数据库对象,包括 如下SQL语句:
- CREATE TABLE:创建数据库表
- ALTER TABLE:更改表结构、添加、删除、修改列长度
- DROP TABLE:删除表
- CREATE INDEX:在表上建立索引
- DROP INDEX:删除索引
DCL
DCL用来控制数据库的访问,包括如下SQL语句:
- GRANT:授予a访问权限
- REVOKE:撤销访问权限
- COMMIT:提交事务处理
- ROLLBACK:事务处理回退
- SAVEPOINT:设置保存点
- LOCK:对数据库的特定部分进行锁定
MYSQL安装与使用
MySQL产品的特点
MySQL数据库隶属于MySQLAB公司,总部位于瑞典,后被oracle收购
优点:
- 成本低:开放源代码,一般可以免费试用
- 性能高:执行很快
- 简单:很容易安装和使用
MySql数据库的安装与使用
DBMS分为两类:
- 基于共享文件系统的DBMS (Access )
- 基于客户机——服务器的DBMS(MySQL、Oracle、SqlServer)
Windows平台下下载:http://dev.mysql.com/downloads/mysql
MySql安装
手动创建my.ini文件
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置mysql的安装目录,这里要修改为自己的
basedir=C:/app/mysql-8.0.16-winx64
# 设置mysql数据库的数据的存放目录,这里要修改为自己的
datadir=C:/app/mysql-8.0.16-winx64/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 有新的配置信息继续在这里添加
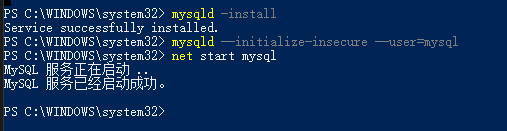
bind-address=127.0.0.1以管理员身份运行cmd (Windows10系统可以右键点击屏幕左下 角的WIN图标,点击Windows PowerShell(管理员)直接运行。) 切换到MySQL 安装目录的bin目录下,执行mysqld -install 命令
出现"Service successfully installed." -->成功
ps: 如果出现"Install/Remove of the Service Denied!",请看一下你是不是在 管理员模式
初始化:mysqld --initialize-insecure --user=mysql
启动mysql服务:net start mysql
服务启动成功
进入mysql环境
mysql服务启动成功后,mysql -u root -p
提示Enter password:
在目录mysql-5.7.25-winx64\mysql-5.7.25-winx64\data中打开
err文件(注:8.0版本默认安装无密码,直接回车即可.)
修改root用户密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY '8716' PASSWORD EXPIRE NEVER;
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '8716';
FLUSH PRIVILEGES; 启动和停止MySQL服务:
方式一:通过计算机管理方式
右击计算机—管理—服务—启动或停止MySQL服务
方式二:通过命令行方式 启动:net start
mysql服务名 停止:net stop mysql服务名
MySQL服务端的登录和退出:
登录
mysql –h 主机名 –u用户名 –p密码
退出
exit
MySql数据库的使用
MySQL的语法规范:
- 不区分大小写
- 每句话用;或\g结尾
- 各子句一般分行写
- 关键字不能缩写也不能分行
- 用缩进提高语句的可读性
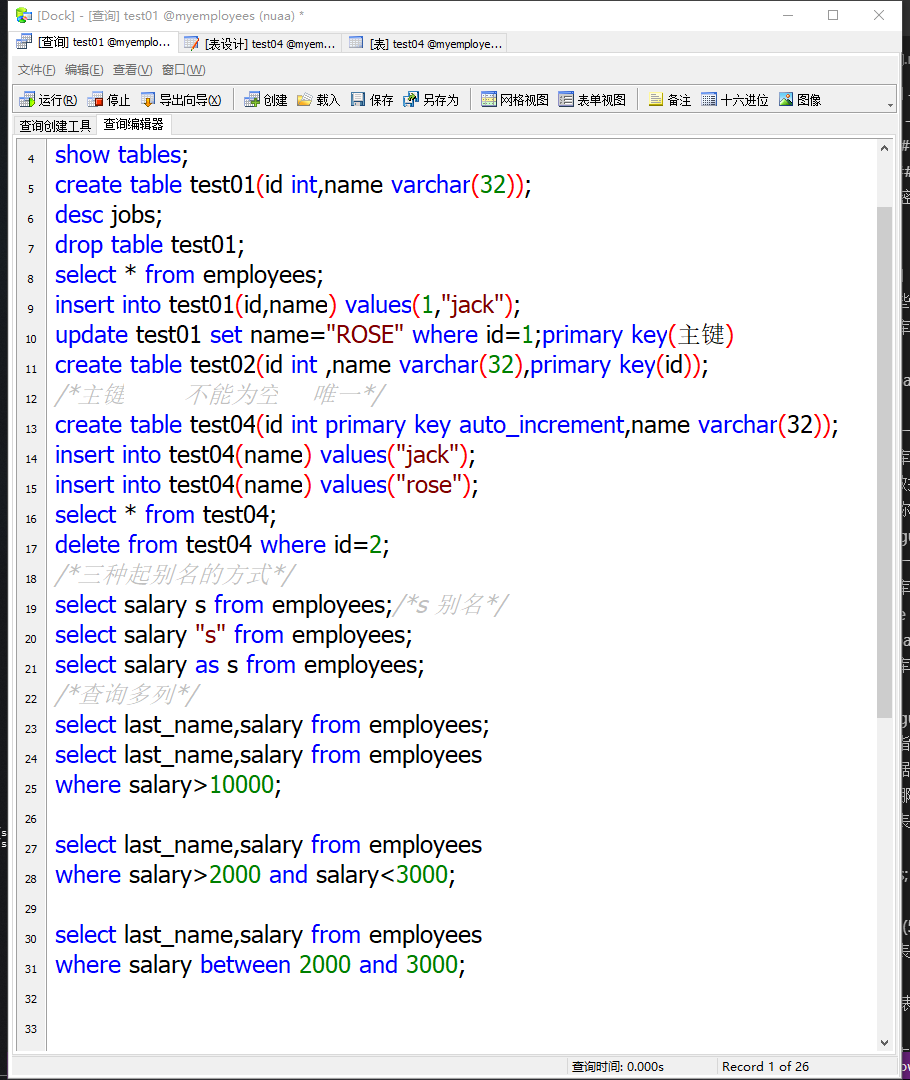
使用1:
- 进入 mysql, 在命令行中输入: mysql –uroot –p#### (其中:####表示 密码)
- 查看 mysql 中有哪些个数据库: show databases; (2)
- 使用一个数据库: use 数据库名称; (3. atguigu)
- 新建一个数据库: create database 数据库名 (1. atguigu)
- 查看指定的数据库中有哪些数据表: show tables; (4, 6, 9)
- 建表: (5)
- 查看表的结构:desc 表名 (7)
- 删除表: drop table 表名 (8)
使用2:
- 查看表中的所有记录: select * from 表名;
- 向表中插入记录:insert into 表名(列名列表) values(列对应的值的列表);
- 注意:插入 varchar 或 date 型的数据要用 单引号 引起来
- 修改记录: update 表名 set 列1 = 列1的值, 列2 = 列2的值 where …
- 删除记录: delete from 表名 where ….
使用3:
- 查询所有列: select * from 表名;
- 查询特定的列: select 列名1,列名2, … from 表名
- 对查询的数据进行过滤:使用 where 子句
- 运算符:
between,>,in,like,is not null,order by
图形化界面客户端的使用
数据处理之查询
基本的SELECT语句
SELECT *|{[DISTINCT] column|expression [alias],...
FROM table;选择全部列:
select * from departments;选择特定的列:
select department_id from departments;注意:
- SQL 语言大小写不敏感
- SQL 可以写在一行或者多行
- 关键字不能被缩写也不能分行
- 各子句一般要分行写
- 使用缩进提高语句的可读性
显示表结构
使用 DESCRIBE命令,表示表结构
DESC[RIBE]tablename
DESCRIBE employees列的别名
列的别名:
重命名一个列
便于计算
紧跟列名,也可以在列名和别名之间加入关键字
“ AS ” , 别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写
SELECT last_name AS name, commission_pct comm
FROM employees;过滤和排序数据
比较运算
SELECT last_name, salary FROM employees WHERE salary <= 3000;其他比较运算:between and,in(set),like,is NULL
BETWEEN
包含边界
SELECT last_name, salary
FROM employees
WHERE salary BETWEEN 2500 AND 3500;IN
SELECT employee_id, last_name, salary, manager_id
FROM employees
WHERE manager_id IN (100, 101, 201);LIKE
使用 LIKE 运算选择类似的值
选择条件可以包含字符或数字:
代表零个或多个字符(任意个字符)
_ 代表一个字符
SELECT first_name
FROM employees
WHERE first_name LIKE '_S%';NULL
SELECT last_name, manager_id
FROM employees
WHERE manager_id IS NULL;逻辑运算
AND
OR
NOT
ORDERBY子句
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date ;降序排序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC ;按别名排序
SELECT employee_id, last_name, salary*12 annsal
FROM employees
ORDER BY annsal;where 语句当中不能使用别名
多个列排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;组函数
什么是组函数
组函数作用于一组数据,并对一组数据返回一个值
组函数类型
AVG()
COUNT()
MAX()
MIN()
SUM()分组数据
GROUP BY 子句
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];明确:WHERE一定放在FROM后面
HAVING子句
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];使用 HAVING过滤分组:
-
行已经被分组
-
使用了组函数
-
满足HAVING子句中条件的分组将被显示
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
多表查询
Mysql连接
使用连接在多个表中查询数据:
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;等值连接:
SELECT beauty.id,NAME,boyname FROM beauty ,boys
WHERE beauty.`boyfriend_id`=boys.id;区分重复的列名:
- 使用表名前缀在多个表中区分相同的列
- 在不同表中具有相同列名的列可以用表的别名加以区分
- 如果使用了表别名,则在select语句中需要使用表别名代替表名
- 表别名最多支持32个字符长度,但建议越少越好
表的别名:
使用别名可以简化查询
使用表名前缀可以提高执行效率。
SELECT bt.id,NAME,boyname
FROM beauty bt,boys b
WHERE bt.`boyfriend_id`=b.id ;使用ON子句创建连接
自然连接中是以具有相同名字的列为连接条件的
可以使用ON 子句指定额外的连接条件
这个连接条件是与其它条件分开的
ON 子句使语句具有更高的易读性
Join连接:
分类:
内连接 [inner] join on –
外连接
左外连接 left [outer] join on
右外连接 right [outer] join on
ON子句
SELECT bt.id,NAME,boyname FROM beauty bt
Inner join boys b
On bt.`boyfriend_id`=b.id ;连接多个表
使用ON 子句创建多表连接:
SELECT employee_id, city, department_name FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l
ON d.location_id = l.location_id;举例:
/*内连接 [inner] join on*/
select beauty.name,boys.boyName from beauty
inner join boys
on beauty.boyfriend_id=boys.id;
/*左外连接 left outer join on*/
select beauty.name,boys.boyName from beauty
left outer join boys
on beauty.boyfriend_id=boys.id;
/*右外连接right outer join on*/
select beauty.name,boys.boyName from beauty
right outer join boys
on beauty.boyfriend_id=boys.id;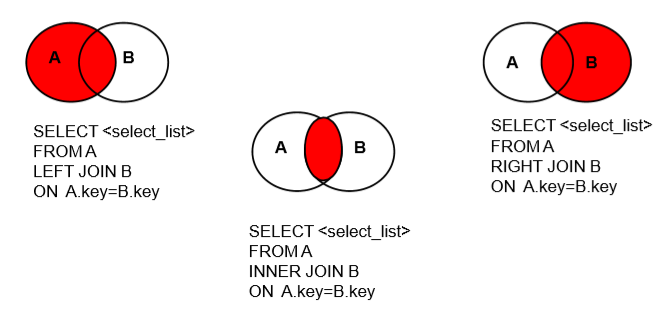
select beauty.name,boys.boyName from beauty
left outer join boys
on beauty.boyfriend_id=boys.id
where boys.boyName is null;
select beauty.name,boys.boyName from beauty
right outer join boys
on beauty.boyfriend_id=boys.id
where beauty.name is null;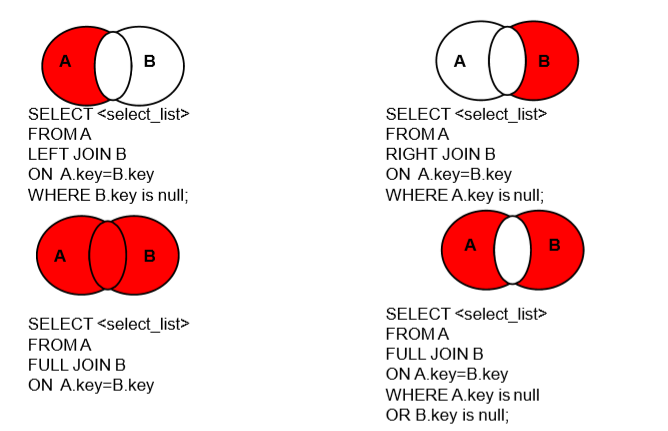
select beauty.name,boys.boyName from beauty
left outer join boys
on beauty.boyfriend_id=boys.id
union
select beauty.name,boys.boyName from beauty
right outer join boys
on beauty.boyfriend_id=boys.id;常见函数
字符函数
大小写控制函数
lower全转换为小写
upper全转换为大写
/*lower upper*/
select lower(last_name) from employees;
select upper(last_name) from employees;字符控制函数
select concat(first_name,"_",last_name)from employees; /*字符串连接*/
select last_name,substring(last_name,1,3)from employees;/*选择从第一个到第三个字符*/
select first_name,email,length(email)from employees;
select instr("HelloWorld","o");/*返回第一个特定的字符所处的位置*/
select lpad(salary,10,'*') from employees;/**字符指定长度 ,不够补特定字符*/
select rpad()
select trim(" A B C DE F G C S A "); /*去除字符串首尾的空格*/
select ltrim(" A B C DE F G C S A ");/*去除左空格*/
select trim("A" from "AA A V D B FD D A");/*左右同时去除A直到遇到不为A的字符*/
select trim(both"A" from "AA A V D B FD D A");/*与上面的相同*/
select trim(leading"A" from "AA A V D B FD D A");
select trim(trailing"A" from "AA A V D B FD D A");
select replace('HelloWorld','o','O');数学函数
ROUND:四舍五入
TRUNCATE: 截断
MOD:求余
select round(123.456,2);
select truncate(12345.0678,2);
select truncate(12345.0678,-1);
select mod(1600,300);日期函数
now():获取当前日期
str_to_date:将日期格式的字符转换成指定格式的日期
date_format:将日期转换成字符
select now();
select str_to_date("2019-07-16","%Y-%m-%d");
select date_format("2018/6/6","%Y年%m月%d日");| 序号 | 格式符 | 功能 |
|---|---|---|
| 1 | %Y | 四位的年份 |
| 2 | %y | 2位的年份 |
| 3 | %m | 月份(01,02…11,12 |
| 4 | %c | 月份(1,2,…11,12) |
| 5 | %d | 日(01,02,…) |
| 6 | %H | 小时(24小时制) |
| 7 | %h | 小时(12小时制) |
| 8 | %i | 分钟(00,01…59) |
| 9 | %s | 秒(00,01,…59) |
其他函数
流程控制函数
在 SQL语句中使用IF-THEN-ELSE逻辑
使用方法: – CASE表达式
select department_id,salary,
case department_id when 10 then salary*1.1
when 20 then salary*1.2
when 30 then salary*1.3
else salary
end ss
from employees;子查询
概念:出现在其他语句内部的select语句,称为子查询或内查询
select first_name from employees
where department_id in(
select department_id from departments
where location_id=1700
)注意:
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
子查询类型
单行子查询
执行单行子查询:
题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id 和工资
select last_name,job_id,salary from employees
where job_id=(
select job_id from employees where employee_id=141
)and salary>=(
select salary from employees where employee_id=143
);在子查询中使用组函数:
题目:返回公司工资最少的员工的last_name,job_id和salary
select last_name,salary from employees
where salary=(
select min(salary)from employees
);HAVING子句中的子查询:
题目:查询最低工资大于40号部门最低工资的部门id和 其最低工资
select department_id,min(salary)from employees
group by department_id
having min(salary)>(
select min(salary)from employees
where department_id=40
);多行子查询
| 操作符 | 含义 |
|---|---|
| IN/NOT IN | 等于列表中的任意一个 |
| ANY | SOME |
| ALL | 和子查询返回的所有值比较 |
使用in操作符:
题目:返回location_id是1400或1700的部门中的所 有员工姓名
select last_name from employees
where department_id in(
select department_id from departments
where location_id in(1400,1700)
);在多行子查询中使用ANY 操作符:
题目:返回其它部门中比job_id为‘IT_PROG’部门任一工资低的员工的员 工号、姓名、job_id以及salary
select employee_id,last_name,job_id,salary from employees
where salary<any(
select salary from employees
where job_id ="IT_PROG"
)and department_id not in(
select department_id from employees
where job_id ="IT_PROG"
);在多行子查询中使用ALL 操作符:
题目:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工 的员工号、姓名、job_id 以及salar
select employee_id,last_name,job_id,salary from employees
where salary<all(
select salary from employees
where job_id ="IT_PROG"
)and department_id not in(
select department_id from employees
where job_id ="IT_PROG"
);创建和管理表
创建数据库
创建一个保存员工信息的数据库 :
– create database employees;
相关其他命令 :
– show databases;查看当前所有数据库
– use employees;“使 用”一个数据库,使其作为当前数据库
命名规则
数据库名不得超过30个字符,变量名限制为29个
必须只能包含 A–Z, a–z, 0–9, _共63个字符
不能在对象名的字符间留空格
必须不能和用户定义的其他对象重名
必须保证你的字段没有和保留字、数据库系统或常用方法冲突
保持字段名和类型的一致性,在命名字段并为其指定数 据类型的时候 一定要保证一致性;假如数据类型在一 个表里是整数,那在另一个表 里可就别变成字符型了
创建表
语法:
CREATE TABLE dept (deptno INT(2), dname VARCHAR(14), loc VARCHAR(13)); 确认:
DESCRIBE dept常用数据类型:
| INT | 使用4个字节保存整数数据 |
|---|---|
| CHAR(size) | 定长字符数据。若未指定,默认为1个字符,最大长度255 |
| VARCHAR(size) | 可变长字符数据,根据字符串实际长度保存,必须指定长度 |
| FLOAT(M,D) | 单精度,M=整数位+小数位,D=小数位。 D<=M<=255,0<=D<=30 , 默认M+D<=6 |
| DOUBLE(M,D) | 双精度。D<=M<=255,0<=D<=30,默认M+D<=15 |
| DATE | 日期型数据,格式’YYYY -MM-DD’ |
| BLOB | 二进制形式的长文本数据,最大可达4G |
| TEXT | 长文本数据,最大可达4G |
创建表 :
CREATE TABLE emp (
#int类型,自增 emp_id INTAUTO_INCREMENT,
#最多保存20个中英文字符 emp_name CHAR (20),
# 总位数不超过15位 salary DOUBLE,
#日期类型 birthday DATE,
#主键 PRIMARY KEY (emp_id)
) ;使用子查询创建表:
create table t like employees;/*复制表结构*/
insert into t select * from employees;/*插入数据*/管理表
ALTERTABLE语句
使用 ALTERTABLE语句可以实现:
- 向已有的表中添加列
- 修改现有表中的列
- 删除现有表中的列
- 重命名现有表中的列
追加一个新列
alter table t add pwd varchar(32) default 0;修改一个列
可以修改列的数据类型, 尺寸和默认值
对默认值的修改只影响今后对表的修改
alter table t modify pwd char(12) default 100;删除一个列
alter table t drop pwd;重命名一个列
alter table change email mail varchar(24);删除表
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
DROP TABLE 语句不能回滚
drop table t;清空表
TRUNCATE语句不能回滚
truncate table t;可以使用 DELETE 语句删除数据,可以回滚 :
begin;
select * from t;
delete from t;
select * from t;
rollback;
select * from t;
commit;改变对象的名称
alter table t rename to ttt;常见的数据类型
数值类型
整型:
| 整数类型 | 字节 | 范围 |
|---|---|---|
| Tinyint | 1 | 有符号:-128~127 无符号 :0~255 |
| Smallint | 2 | 有符号:-32768~32767 无符号 :0~65535 |
| Mediumint | 3 | 有符号:-8388608~8388607 无符号:0~1677215 |
| Int、integer | 4 | 有符号:- 2147483648~2147483647 无符号:0~4294967295 |
| Bigint | 8 | 有符号: -9223372036854775808 ~9223372036854775807 无符号 :0~ 9223372036854775807*2+1 |
drop table if exists t;
create table t(id tinyint(10));
insert into t values(100);
insert into t values(-128);
insert into t values(128);
insert into t values(255);
delete from t where id=-128;
alter table t modify id tinyint(10) unsigned;
alter table t modify id tinyint(10) zerofill;
create table t(id integer(10));
insert into t values(100);
insert into t values(-128);
insert into t values(128);
insert into t values(255);
alter table t modify id integer(10) zerofill;zerofill: 填充0(如果声明了zerofill,该列会自动设为unsigned)
影响数字的显示方式:
如果一个数字的宽度小于所允许的最大宽度,这个值前面会用0填充
如果宽度大于所允许的最大宽度但不超过取值范围,以实际的取值范围为准,不填0;
超出取值范围的报错不存储
示例:
mysql> create table t1(id int zerofill); #默认显示宽度10
mysql> insert into t1 values(-1); #取值范围:0--4294967295
ERROR 1264 (22003): Out of range value for column 'id' at row 1
mysql> insert into t1 values(123);
mysql> insert into t1 values(12300);
mysql> insert into t1 values(1.123);
mysql> select * from t1;结果:
| id |
|---|
| 0000000123 |
| 0000012300 |
| 0123456789 |
| 0000000001 |
解析:因为建表的设置是int整数,小数点后的数会四舍五入
小数:
| 浮点类型 | 字节 | 范围 |
|---|---|---|
| float | 4 | ±1.75494351E-38~±3.402823466E+38 |
| double | 8 | ±2.2250738585072014E-308~ ±1.7976931348623157E+308 |
| 定点类型 | 字节 | 范围 |
|---|---|---|
| DEC(M,D) DECIMAL(M,D | M+2 | 最大取值范围与double相同,给定decimal的有效取值范围由M和D决定 |
length(precision):在一个浮点数据类型中可以指定长度,来确定具体的浮点类型:
0~24:单精度float,从第6位有效位,进行四舍五入存储
25~30:双精度double,从第16位有效位,进行四舍五入存储
使用两个参数来指定浮点类型:
单精度float(m,d):m表示精度(0~24),d表示小数位数
双精度double(m,d):m表示精度(25~30),d表示小数位数
栗子:
create table t(id float(5,3));/*5:总的位数 3:小数位数 2:整数位数 超出报错*/
insert into t values(123);
insert into t values(123456);
insert into t values(123456789);
insert into t values(123456789.123456789);
insert into t values(1.23456789);结果:
| id |
|---|
| 1.235 |
栗子:
create table t (id double(20,3));
insert into t values(123);
insert into t values(123456);
insert into t values(123456789);
insert into t values(89.1234567845678456789);
insert into t values(1.23456789234567892345678923456789);结果:
| id |
|---|
| 123 |
| 123456 |
| 123456789 |
| 89.123 |
| 1.235 |
栗子:
create table t (id decimal(10,3));/*dec的小树位数是定数*/
insert into t values(123.1);
insert into t values(123456);
insert into t values(123456789);
insert into t values(89.1234567845678456789);
insert into t values(1.23456789234567892345678923456789);结果:
| id |
|---|
| 123.1 |
| 123456 |
| 89.123 |
| 1.235 |
位类型:
| 位类型 | 字节 | 范围 |
|---|---|---|
| BIT(M) | 1~8 | Bit(1)~Bit(8) |
create table t(id bit(4));
insert into t values(4);
insert into t values(15);位主要是用来存放二进制数,可以使用bin()、hex()函数来进行查询:
bin()---显示二进制格式
hex()---显示十六进制格式
mysql> create table t7(id bit(4));
mysql> insert into t7 values(2);
mysql> insert into t7 values(13);
mysql> select bin(id),hex(id) from t7;| bin(id) | hex(id) |
|---|---|
| 10 | 2 |
| 1101 | D |
字符类型
char和varchar类型 :
用来保存MySQL中较短的字符串
| 字符串类型 | 最多字符数 | 描述及存储需求 |
|---|---|---|
| char(M) | M | M为0~255之间的整数 |
| varchar(M) | M | M为0~65535之间的整数 |
| tinytext | 可变长度 | 最多255个字符 |
| text | 可变长度 | 最多65535个字符 |
| mediumtext | 可变长度 | 最多2的24次方-1个字符 |
| longtext | 可变长度 | 最多2的32次方-1个字符 |
字符串中的单引号用单引号进行转义
若要存储中文字符串,需要进行字符设置:
create table tableName(列名 varchar(20) character set utf8);
create table tableName(列名 varchar(20) character set gpk);char和varchar的区别:
char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉
char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节
varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255)
所以varchar(4),存入3个字符将占用4个字节
char类型的字符串检索速度要比varchar类型的快
varchar和text的区别:
varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
text类型不能有默认值
varchar可直接创建索引,text创建索引要指定前多少个字符
varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用
binary和varbinary类型:
类似于char和varchar,不同的是它们包含二进制字 符串而不包含非二进制字符串
create table t(id int auto_increment primary key,name varchar(32));
insert into t(name) values(123);
insert into t(name) values("xiao\'ming");
insert into t(name) values('xiao''ming');
Enum类型
又称为枚举类型,要求插入的值必须属于列表中指定的值之一
如果列表成员为1~255,则需要1个字节存储
如果列表成员为255~65535,则需要2个
字节存储最多需要65535个成员!
Set类型
和Enum类型类似,里面可以保存0~64个成员
和Enum类型最大的区别是:
SET类型一次可以选取多个成员
而Enum只能选一个根据成员个数不同,存储所占的字节也不同
/*enmu 1 2 3 4 set 1 2 4 8*/
create table t(id int auto_increment primary key,sex enum("男","女"),hobby set("singing","jumping","rap","basketball"));
insert into t(sex,hobby)values("男","singing,jumping,rap,basketball");
insert into t(sex,hobby)values(2,3);
insert into t(sex,hobby)values(2,15);日期类型
| 日期和时间类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| date | 4 | 1000-01-01 | 9999-12-31 |
| datetime | 8 | 1000-01-01 00:00:00 | 9999-12-31 13:59:59 |
| timestamp | 4 | 19700101080001 | 2038年的某个时刻 |
| time | 3 | -838:59:59 | 838:59:59 |
| year | 1 | 1901 | 2156 |
datetime和timestamp的区别:
1、Timestamp支持的时间范围较小,取值范围: 19700101080001——2038年的某个时间 Datetime的取值范围:1000-1-1 —9999—12-31
2、timestamp和实际时区有关,更能反映实际的日期,而 datetime则只能反映出插入时的当地时区
3、timestamp的属性受Mysql版本和SQLMode的影响很大
create table t(sj date);
insert into t values(19900101);
create table t(sj datetime);
insert into t values(19900101001100);获得当前日期时间的函数
获得当前日期+时间(date+time)函数:now()、sysdate()
区别:now()在执行开始时值就得到了,sysdate()在函数执行时动态得到值
获得当前日期curdate()、获得当前时间curtime()
-
日期字符串转换函数format:
date_format(date,format)
---将日期date按照给定的模式format转换成字符串
time_format(time,format)
---将时间time按照给定的模式format转换成字符串,format中只可以使用时、分、秒、微秒模式元素
-
日期字符串转换函数
str_to_date(str,format)
---将字符串str以指定的模式format转换成日期
约束与分页
约束
约束是限制用户输入到表中的数据的值的范围
约束种类:
非空约束(not null)
唯一性约束(unique)
主键约束(primary key) PK
外键约束(foreign key) FK
检查约束(目前MySQL不支持、Oracle支持)
非空约束(not null)
用not null约束的字段不能为null值,必须给定具体的数据
创建表,给字段添加非空约束(创建用户表,用户名不能为空)
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null
-> );Query OK, 0 rows affected (0.08 sec)
如果没有插入name字段数据,则会报错
mysql> insert into t_user (id) values(1);ERROR 1364 (HY000): Field 'name' doesn't have a default value
唯一性约束(unique)
unique约束的字段,具有唯一性,不可重复,但可以为null
创建表,保证邮箱地址唯一(列级约束)
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> email varchar(128) unique
-> );Query OK, 0 rows affected (0.03 sec)
表级约束
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> email varchar(128),
-> unique(email)
-> );如果插入相同email会报错
mysql> insert into t_user(id,name,email) values(1,'xlj','932834897@qq.com');Query OK, 1 row affected (0.00 sec)
mysql> insert into t_user(id,name,email) values(2,'jay','932834897@qq.com');ERROR 1062 (23000): Duplicate entry '932834897@qq.com' for key 'email'
使用表级约束,给多个字段联合约束
联合约束,表示两个或以上的字段同时与另一条记录相等,则报错
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> email varchar(128),
-> unique(name,email)
-> );Query OK, 0 rows affected (0.01 sec)
插入第一条数据
mysql> insert into t_user(id,name,email) values(1,'xxx','qq.com');Query OK, 1 row affected (0.05 sec)
插入第二条数据如果是与联合字段中的一条相同另一条相同,也是可以的
mysql> insert into t_user(id,name,email) values(2,'mmm','qq.com');Query OK, 1 row affected (0.05 sec)
插入第三条数据,如果与联合字段都相同,则报错
mysql> insert into t_user(id,name,email) values(3,'mmm','qq.com');ERROR 1062 (23000): Duplicate entry 'mmm-qq.com' for key 'name'
表级约束可以给约束起名字
方便以后通过这个名字来删除这个约束
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> email varchar(128),
-> constraint t_user_email_unique unique(email)
-> );Query OK, 0 rows affected (0.06 sec)
constraint是约束关键字,t_user_email_unique自己取的名字
主键约束(primary key) PK
表设计时一定要有主键
表中的某个字段添加主键约束后,该字段为主键字段,主键字段中出现的每一个数据都称为主键值
主键约束与“not null unique”区别:
给某个字段添加主键约束之后,该字段不能重复也不能为空,效果和”not null unique”约束相同,但是本质不同
主键约束除了可以做到”not null unique”之外,还会默认添加”索引——index”
无论是单一主键还是复合主键,一张表主键约束只能有一个(约束只能有一个,但可以作用到好几个字段)
单一主键:给一个字段添加主键约束
复合主键:给多个字段联合添加一个主键约束(只能用表级定义)
单一主键(列级定义)
mysql> create table t_user(
-> id int(10) primary key,
-> name varchar(32)
-> );Query OK, 0 rows affected (0.07 sec)
单一主键(表级定义)
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> constraint t_user_id_pk primary key(id)
-> );Query OK, 0 rows affected (0.01 sec)
复合主键(表级定义)
mysql> create table t_user(
-> id int(10),
-> name varchar(32) not null,
-> email varchar(128) unique,
-> primary key(id,name)
-> );
Query OK, 0 rows affected (0.05 sec)
在MySQL数据库提供了一个自增的数字,专门用来自动生成主键值,主键值不用用户维护,自动生成,自增数从1开始,以1递增(auto_increment)
mysql> create table t_user(
-> id int(10) primary key auto_increment,
-> name varchar(32) not null
-> );Query OK, 0 rows affected (0.03 sec)
插入两行记录,id主键值会自动增加
mysql> insert into t_user(name) values('jay');Query OK, 1 row affected (0.04 sec)
mysql> insert into t_user(name) values('man');Query OK, 1 row affected (0.00 sec)
mysql> select * from t_user;
| id | name |
|---|---|
| 1 | jay |
| 2 | man |
外键约束(foreign key) FK
什么是外键
若有两个表A、B,id是A的主键,而B中也有id字段,则id就是表B的外键,外键约束主要用来维护两个表之间数据的一致性
按外键约束的字段数量分类:
单一外键:给一个字段添加外键约束
复合外键:给多个字段联合添加一个外键约束
一张表可以有多个外键字段(与主键不同)
栗子:
设计数据库表,用来存储学生和班级信息
两种方案
方案一:将学生信息和班级信息存储到一张表
sno sname classno cname
1 jay 100 浙江省第一中学高三1班
2 lucy 100 浙江省第一中学高三1班
3 king 200 浙江省第一中学高三2班缺点:数据冗余,比如cname字段的数据重复太多
方案二:将学生信息和班级信息分开两张表存储
学生表(添加单一外键)
sno(pk) sname classno(fk)
1 jack 100
2 lucy 100
3 king 200班级表
cno(pk) cname
100 浙江省第一中学高三1班
200 浙江省第一中学高三2班结论:
为了保证学生表中的classno字段中的数据必须来自于班级表中的cno字段中的数据,有必要给学生表中的classno字段添加外键约束
注意点:
外键值可以为null
外键字段去引用一张表的某个字段的时候,被引用的字段必须具有unique约束
有了外键引用之后,表分为父表和子表
班级表:父表
学生表:子表
创建先创建父表
删除先删除子表数据
插入先插入父表数据
存储学生班级信息:
mysql> drop table if exists t_student;
mysql> drop table if exists t_class;
mysql> create table t_class(
-> cno int(10) primary key,
-> cname varchar(128) not null unique
-> );
mysql> create table t_student(
-> sno int(10) primary key auto_increment,
-> sname varchar(32) not null,
-> classno int(3),
-> foreign key(classno) references t_class(cno)
-> );
mysql> insert into t_class(cno,cname) values(100,'aaaaaaxxxxxx');
mysql> insert into t_class(cno,cname) values(200,'oooooopppppp');
mysql> insert into t_student(sname,classno) values('jack',100);
mysql> insert into t_student(sname,classno) values('lucy',100);
mysql> insert into t_student(sname,classno) values('king',200);结果:
班级表t_class:
mysql> select * from t_class;| cno | cname |
|---|---|
| 100 | aaaaaaxxxxxx |
| 200 | oooooopppppp |
学生表t_student:
mysql> select * from t_student;| sno | sname | classno |
|---|---|---|
| 1 | jack | 100 |
| 2 | lucy | 100 |
| 3 | king | 200 |
上表中找出每个学生的班级名称
mysql> select s.*,c.* from t_student s join t_class c on s.classno=c.cno;| sno | sname | classno | cno | cname |
|---|---|---|---|---|
| 1 | jack | 100 | 100 | aaaaaaxxxxxx |
| 2 | lucy | 100 | 100 | aaaaaaxxxxxx |
| 3 | king | 200 | 200 | oooooopppppp |
分页
mysql中用limit 进行分页有两种方式
语句1:select * from student limit 9,4
语句2:slect * from student limit 4 offset 9
语句1和2均返回表student的第10、11、12、13行 ,第一个参数表示从该参数的下一条数据开始,第二个参数表示每次返回的数据条数
语句2中的4表示返回4行,9表示从表的第十行开始
假设 pageSize表示每页要显示的条数,pageNumber表示页码,那么 返回第pageNumber页,每页条数为pageSize的sql语句:
代码示例:
语句3:select from studnet limit (pageNumber-1)pageSize,pageSize
语句4:select from student limit pageSize offset (pageNumber-1)pageSize
事务
事务:事务由单独单元的一个或多个SQL语句组成,在这 个单元中,每个MySQL语句是相互依赖的。而整个单独单 元作为一个不可分割的整体,如果单元中某条SQL语句一 旦执行失败或产生错误,整个单元将会回滚。所有受到影响的数据将返回到事物开始以前的状态;如果单元中的所有SQL语句均执行成功,则事物被顺利执行
事务的特点
- 原子性(Atomicity) 原子性是指事务是一个不可分割的工作单位,事务中的操作要么 都发生,要么都不发生。
- 一致性(Consistency) 事务必须使数据库从一个一致性状态变换到另外一个一致性状态 。
- 隔离性(Isolation) 事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个 事务内部的操作及使用的数据对并发的其他事务是隔离的,并发 执行的各个事务之间不能互相干扰。
- 持久性(Durability) 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是 永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
事务的使用
以第一个 DML语句的执行作为开始
以下面的其中之一作为结束:
- COMMIT 或 ROLLBACK语句
- DDL 或 DCL语句(自动提交)
- 用户会话正常结束
- 系统异常终了
数据库的隔离级别
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制,就会导致各种并发问题:
脏读: 对于两个事务 T1,T2,T1 读取了已经被 T2 更新但还没有被提交的字段. 之后,若 T2 回滚,T1读取的内容就是临时且无效的
不可重复读: 对于两个事务T1,T2,T1 读取了一个字段, 然后 T2 更新了该字段. 之后,T1再次读取同一个字段, 值就不同了
幻读: 对于两个事务T1,T2,T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行之后, 如果 T1 再次读取同一个表, 就会多出几行.
数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响,避免各种并发问题
一个事务与其他事务隔离的程度称为隔离级别. 数据库规定了多种事务隔 离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就 越好,但并发性越弱
数据库的隔离级别
数据库提供的 4种事务隔离级别:
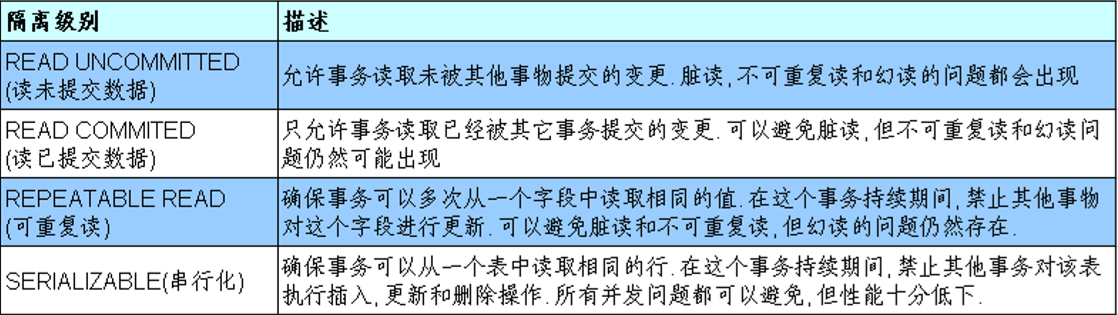
Oracle支持的2种事务隔离级别:READCOMMITED, SERIALIZABLE
Oracle默认的事务隔离级别为:READ COMMOTED
Mysql支持 4种事务隔离级别.Mysql默认的事务隔离级别 为:REPEATABLE READ
在 MySql中设置隔离级别:
每启动一个 mysql程序,就会获得一个单独的数据库连接.每个数据库连接都有一个全局变量 @@tx_isolation,表示当前的事务隔离级别
查看当前的隔离级别:SELECT@@tx_isolation;
设置当前 mySQL连接的隔离级别:
set transaction isolation level readcommitted;
设置数据库系统的全局的隔离级别:
set global transaction isolation level readcommitted;